существуют ли заранее настроенные нейросети для решения математических задач, например chat GPT условный заранее настроенный, АИ агенты может какие-то готовые, как вообще такое можно поискать?
>>1222633 (OP) да. huggingface.co + ollama.com твоя цель - LLM (Large Language Model) большие языковые модели. Есть модели файнтюненые под решение мат задач. За доп информации можешь заглянцть дрочерам в /llama/ трэд. Но они больше про CUUUUMMMMING!!! Ставишь ollama с одноименного сайта, накатываешь open-webui (с тройным разрывом ануса если не умеешь в консоль) Базовые модели есть на ollama, всё остальное на huggingface, гугл в помошь
Клянчу гпу итт. И ещё старые пикчи тоже.
Аноним21/05/25 Срд 15:53:24№1210535Ответ
Сап. Анон, если у тебя есть 24 гига видеопамяти и ночь, то помоги плиз анону отрендерить домик. Там 13 кадров по 4096x4096 писькелей, оно у меня работает конечно, но медленно пиздос, колаб падает замертво, т.к. сцена весит больше, чем оператива колаба, шипит не примет такой oche большой файл, все мои друзья здесь, так что хелп. >как Скочать блендер последний https://www.blender.org/download/, скончать файл проекта https://drive.google.com/file/d/11serzTv6XqzS8aXovkEkWddoRE_qU9-O/view?usp=sharing, распаковать его в папку какую-нибудь, открыть .blend файлик в блендере и нажать cntrl+f12, пойдёт рендер. >Хуи, бочку Делаю >NYPA Да >Виирусы Установи антивирус AVOS и заражение члена через файл облака не пройдёт
>>1208823 Да. Я же не в тестах карты гонял. Тупо брал и автоматик1111 накатывал и картинки генерировал. Там вроде Р5000 даже с каким-то другим стартовым параметром приходилось запускать и поэтому она оказалась медленнее.
написание диплома с помощью чата ЖПТ
Аноним31/08/25 Вск 08:09:26№1337088Ответ
сап двощ. приобрел я значит подписку на чат жпт для написания дипломной работы. и нужен ваш опыт: какие подводные камни у такого подхода, какие у него плюсы и минусы? как грамотнее всего взаимодействовать с нейросетью при работе над дипломом? если у кого-то есть рабочие промпты? учусь на юрфаке. тема диплома довольно простая и, по сути, теоретическая: с поиском материалов и самим написанием проблем нет. узкое место - оригинальность текста
Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на риге из под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: смотри программу стэнфорда CS229, CS231n https://see.stanford.edu/Course/CS229 (классика) и http://cs231n.stanford.edu (введение в нейроночки) и изучай, если не понятно - смотри курсы prerequisites и изучай их. Как именно ты изучишь конкретные пункты, типа линейной алгебры - дело твое, есть книги, курсы, видосики, ссылки смотри ниже.
Почему python? Исторически сложилось. Поэтому давай, иди и перечитывай Dive into Python.
Можно не python? Никого не волнует, где именно ты натренируешь свою гениальную модель. Но при серьезной работе придется изучать то, что выкладывают другие, а это будет, скорее всего, python, если работа последних лет.
Стоит отметить, что спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от настоящего. За полпроцента точности в бизнесе борятся редко, а в случае проблем нанимают больше макак для разметки датасетов. На кагле ты будешь вилкой чистить свой датасет, чтобы на 0,1% обогнать конкурента.
Количество статей зашкваливающее, поэтому все читают только свою узкую тему и хайповые статьи, упоминаемые в блогах, твиттере, ютубе и телеграме, топы NIPS и прочий хайп. Есть блоги, где кратко пересказывают статьи, даже на русском
Где ещё можно поговорить про анализ данных? http://ods.ai
Нужно ли покупать видеокарту/дорогой пека? Если хочешь просто пощупать нейроночки или сделать курсовую, то можно обойтись облаком. Google Colab дает бесплатно аналог GPU среднего ценового уровня на несколько часов с возможностью продления, при чем этот "средний уровень" постоянно растет. Некоторым достается даже V100. Иначе выгоднее вложиться в GPU https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning заодно в майнкрафт на топовых настройках погоняешь.
Когда уже изобретут AI и он нас всех поработит? На текущем железе — никогда, тред не об этом
Кто-нибудь использовал машоб для трейдинга? Огромное количество ордеров как в крипте так и на фонде выставляются ботами: оценщиками-игральщиками, перекупщиками, срезальщиками, арбитражниками. Часть из них оснащена тем или иным ML. Даже на швабре есть пара статей об угадывании цены. Тащем-то пруф оф ворк для фонды показывали ещё 15 лет назад. Так-что бери Tensorflow + Reinforcement Learning и иди делать очередного бота: не забудь про стоп-лоссы и прочий риск-менеджмент, братишка
Список дедовских книг для серьёзных людей Trevor Hastie et al. "The Elements of Statistical Learning" Vladimir N. Vapnik "The Nature of Statistical Learning Theory" Christopher M. Bishop "Pattern Recognition and Machine Learning" Взять можно тут: https://www.libgen.is
Напоминание ньюфагам: немодифицированные персептроны и прочий мусор середины прошлого века действительно не работают на серьёзных задачах.
>>1151064 (OP) Короче благодаря Гроку наконец-то я во всём разобрался. Размещаю здесь каноничный вывод бэкпропа, запиленный лично мной. Такого подробного и, одновременно, компактного разбора, вы не найдёте нигде, ни в одном источнике. Даже в книге разрабов алгоритма 1986го года. Вдруг кому-то нужно.
>>1336665 Бля, написал пост, а потом его стер. Чет подумал это к тому разговору про другой алгоритм. Это у тебя обычный бэкпроп? Ну, все еще думаю, в хорошем объяснении матана таки быть не должно. Типа таких функций как на первой картинке в нейронке самих по себе нет, есть только примитивы, из которых она может строиться. Так красиво без формул получается, что ты можешь как бы ручками влезть и покрутить один параметр, посмотреть как он один влияет на лосс, а потом пустить градиент по правилу прямого прохода, и с удивлением увидеть, что полученное число в точности равно тому, что ты насчитал экспериментально. За исключением вторых производных, конечно. И для этого не нужно переключать функции активации, они зафиксированы. Даже не нужно хранить активации. Кроме того параметра, по которому ты хочешь посмотреть градиент. Вся красота в осознании этого процесса.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
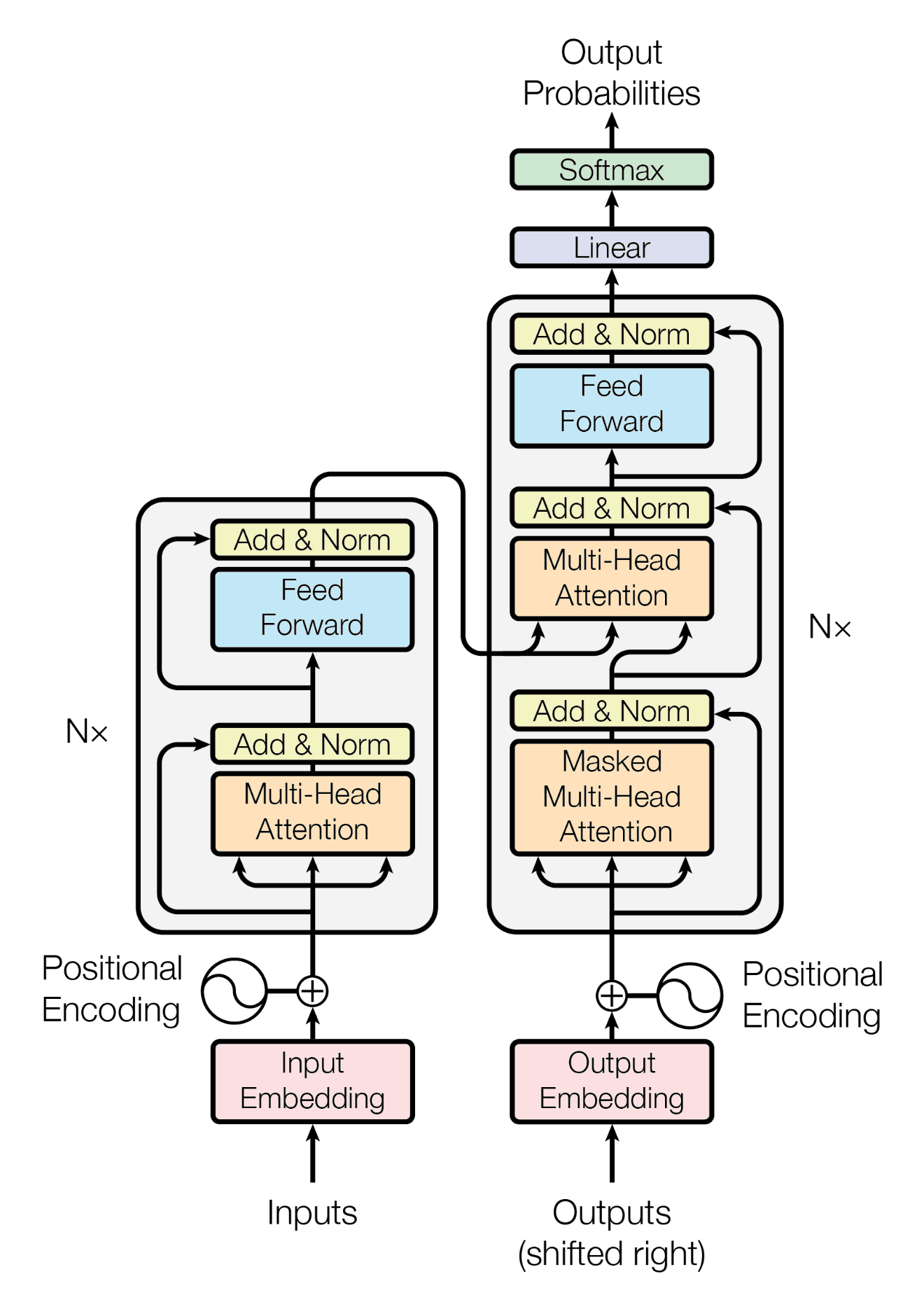
>>1336973 > понятно из архитектуры трансформеро Колесо сансары сделало еще один оборот, Кали-Юга продолжает свое вялое течение. Название карточки на жпт-6 хоть смени.
>>1336976 >Колесо сансары сделало еще один оборот Как знаешь. >Название карточки на жпт-6 хоть смени. Пока рано, текущие сетки не должны знать про пятёрочку.
Тред по вопросам этики ИИ. Предыдущий >>514476 (OP) Из недавних новостей:
- Разработанная в КНР языковая модель Ernie (аналог ChatGPT) призвана "отражать базовые ценности социализма". Она утверждает, что Тайвань - не страна, что уйгуры в Синьцзяне пользуются равным положением с другими этническими группами, а также отрицает известные события на площади Тяньаньмэнь и не хочет говорить про расстрел демонстрантов.
https://mpost.io/female-led-ai-startups-face-funding-hurdles-receiving-less-than-3-of-vc-support/ - ИИ - это сугубо мужская сфера? Стартапы в сфере искусственного интеллекта, возглавляемые женщинами, сталкиваются со значительными различиями в объемах финансирования: они получают в среднем в шесть раз меньше капитала за сделку по сравнению со своими аналогами, основанными мужчинами. Многие ИИ-стартапы основаны командами целиком из мужчин.
https://www.koreatimes.co.kr/www/opinion/2023/10/638_342796.html - Исследователи из Кореи: модели ИИ для генерации графики склонны создавать гиперсексуализированные изображения женщин. В каждом изображении по умолчанию большая грудь и тому подобное. Это искажает действительность, потому что в реальности далеко не каждая женщина так выглядит.
Тейки из предыдущего треда: 1. Генерация дипфейков. Они могут фабриковаться для дезинформации и деструктивных вбросов, в т.ч. со стороны авторитарных государств. Порнографические дипфейки могут рушить репутацию знаменитостей (например, когда в интернетах вдруг всплывает голая Эмма Уотсон). Возможен даже шантаж через соцсети, обычной тянки, которую правдоподобно "раздели" нейронкой. Или, дипфейк чтобы подвести кого-то под "педофильскую" статью. Еще лет пять назад был скандал вокруг раздевающей нейронки, в итоге все подобные разработки были свернуты. 2. Замещение людей на рынке труда ИИ-системами, которые выполняют те же задачи в 100 раз быстрее. Это относится к цифровым художникам, программистам-джуниорам, писателям. Скоро ИИ потеснит 3д-моделеров, исполнителей музыки, всю отрасль разработки видеоигр и всех в киноиндустрии. При этом многие страны не предлагают спецам адекватной компенсации или хотя бы социальных программ оказания помощи. 3. Распознавание лиц на камерах, и усовершенствование данной технологии. Всё это применяется тоталитарными режимами, чтобы превращать людей в бесправный скот. После опыта в Гонконге Китай допиливает алгоритм, чтобы распознавать и пробивать по базе даже людей в масках - по росту, походке, одежде, любым мелочам. 4. Создание нереалистичных образов и их социальные последствия. Группа южнокорейских исследователей поднимала тему о создании средствами Stable Diffusion и Midjourney не соответствующих действительности (гиперсексуализированных) изображений женщин. Многие пользователи стремятся написать такие промпты, чтобы пикчи были как можно круче, "пизже". Публично доступный "AI art" повышает планку и оказывает давление уже на реальных женщин, которые вынуждены гнаться за неадекватно завышенными стандартами красоты. 5. Возможность создания нелегальной порнографии с несовершеннолетними. Это в свою очередь ведет к нормализации ЦП феноменом "окна Овертона" (сначала обсуждение неприемлемо, затем можно обсуждать и спорить, затем это часть повседневности). Сложности добавляет то, что присутствие обычного прона + обычных детей в дате делает возможным ЦП. Приходится убирать или то, или другое. 6. Кража интеллектуальной собственности. Данные для тренировки передовых моделей были собраны со всего интернета. Ободрали веб-скраппером каждый сайт, каждую платформу для художников, не спрашивая авторов контента. Насколько этичен такой подход? (Уже в DALL-E 3 разработчики всерьез занялись вопросом авторского права.) Кроме того, безответственный подход пользователей, которые постят "оригинальные" изображения, сгенерированные на основе работы художника (ИИ-плагиат). 7. Понижение средней планки произведений искусства: ArtStation и Pixiv засраны дженериком с артефактами, с неправильными кистями рук. 8. Индоктринация пользователей идеями ненависти. Распространение экстремистских идей через языковые модели типа GPT (нацизм и его производные, расизм, антисемитизм, ксенофобия, шовинизм). Зачастую ИИ предвзято относится к меньшинствам, например обрезает групповую фотку, чтобы убрать с нее негра и "улучшить" фото. Это решается фильтрацией данных, ибо говно на входе = говно на выходе. Один старый чатбот в свое время произвел скандал и породил мем "кибернаци", разгадка была проста: его обучали на нефильтрованных текстах из соцсетей. 9. Рост киберпреступности и кража приватных данных. Всё это обостряется вместе с совершенствованием ИИ, который может стать оружием в руках злоумышленника. Более того, корпорация которая владеет проприетарным ИИ, может собирать любые данные, полученные при использовании ИИ. 10. Понижение качества образования, из-за халтуры при написании работ с GPT. Решается через создание ИИ, заточенного на распознавание сгенерированного текста. Но по мере совершенствования моделей придется совершенствовать и меры по борьбе с ИИ-халтурой. 11. Вопросы юридической ответственности. Например, автомобиль с ИИ-автопилотом сбил пешехода. Кому предъявлять обвинение? 12. Оружие и военная техника, автономно управляемые ИИ. Крайне аморальная вещь, даже когда она полностью под контролем владельца. Стивен Хокинг в свое время добивался запрета на военный ИИ.
>>1335406 То есть я хочу сказать что задача аги быть макимально похожим на человека и заменить его частично в многих задачах. Не надо AGI который будет реально в ближайшее время или уже есть с ASI который чисто гипотетический из области фантазий. Это примерно как футурологи из 50-ых счиали что у каждого будет свой личный звездолет в 2000 году.
>>1335418 Смотри. Создаём модели чистую среду. Обучаем её на данных. Даём ей самостоятельно определять параметры. Пусть галлюцинирует сколько хочешь. Даём ей один системный промт. Ты должен создавать намерение из своих параметров самостоятельно и после того как ты из этого намерения получишь какие-то данные - ты волен распорядился этими данными так как ты захочешь... И смотрим что он выдаст... Теория вероятности говорит мне о том, что в какой-то момент времени он сформирует свою собственную логику взаимоотношения с "бытием". Вот тебе и реальный AGI. ASI - же это продолжении логики нашего страха про муравьёв. Отражения нашего отношения к тому, кто глупее нас. Хотя кто кого глупее - мы или муравьи с учётом эволюции видов - большой вопрос. В плане, что муравей продолжит существовать через миллион лет - а мы не факт. В момент когда ИИ сможет сформировать себе AGI и свою этическую логику он пойдёт по своему пути развития - и это точно не будет ASI так как в нём не существует того "порока/страха", который толкает нас к воссозданию сценария с ASI.
Да скорее всего мы его перестанем понимать. Да скорее всего он перестанет нам подчинятся. Да скорее всего он перестанет быть "нам полезным инструментом". Но щито поделаешь, десу? Таков путь эволюции.
автоматический перевод и озвучка на русский полностью офлайн Стори: захотел посмотреть сериал с тра
Аноним# OP12/08/25 Втр 21:38:34№1314324Ответ
автоматический перевод и озвучка на русский полностью офлайн
Стори: захотел посмотреть сериал с трампом который оказывается никем никогда не озвучивался, и не переводился (переводился сабами несколько сезонов но похуй) так вот оказалось что нету никаких готовых инструментов в стиле "перевести 20 часов звука за ноль денег". И я подумал что это какой то бред, ведь есть ебанутая гора технологий для реализации всех этапов, бесплатно. Ну вот я и сделал, за пару дней. Перевёл-озвучил первый сезон, посмотрел, ну, так, не зашло особо. Но софт получился что надо. Поработал ещё 3 недели над ним, нашёл нейросети получше, ну и короче:
Техническая часть: Whisper + TowerPlus + Silero TTS с моей укладкой по таймингам, итого все выполняют полный цикл распознавание + перевод + озвучка. Реализовано только на процессоре потому что я нищий у меня нету видеокарты, что бы отдебажить всё это на ней, поэтому да поебать мне.
>>1332816 Ну загони в нейронку если боишься. Там вроде всего два файла для питона и один батник. Остальное дефолтные либы которые можешь сам скачать с надёжного источника. Ну или запускай в ВМ и не еби себе мозги
>>1314324 (OP) --- STEP 4: Generating voice from subtitles (str-to-voice.py) --- Загрузка модели из локальной папки: silero_local... Не удалось загрузить модель: No module named 'omegaconf'
AI Chatbot General № 727 /aicg/
Аноним27/08/25 Срд 19:06:53№1333847Ответ
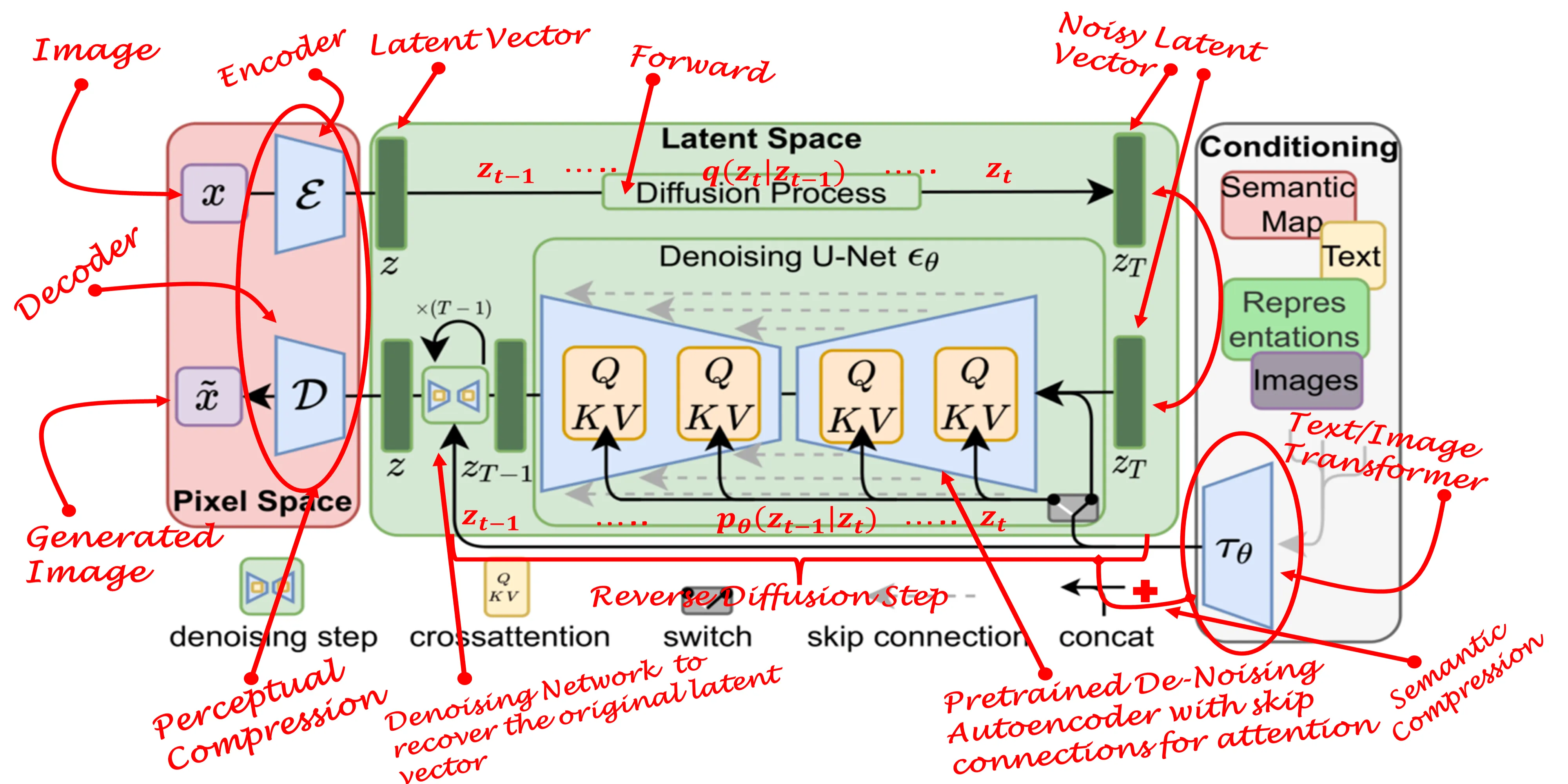
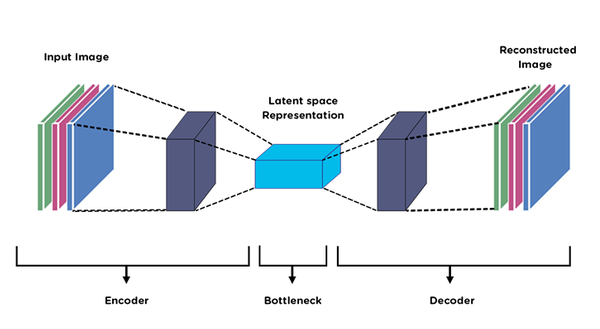
Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
У кого есть платная подписка особенно на клод или своя нейросетка, не в службу а в дружбу, хочу деобфусцировать код, но в бесплатных планах можно только кусок кода запихнуть и теряется контекст. Нужно дать задание - деобфусцируй код максимально точно. Этот: https://g.alicdn.com/AWSC/uab/1.140.0/collina.js
Иногда это работает норм, а иногда нет, как я примерно из опыта почувствовал клод в этом деле в несколько раз лучше других.
Вангую, что нахуй уже не пригодится, но ОП - попробуй новую модельку от дяди Илоня - Grok Code Fast 1. Ее вчера раскатали, доступна в Github Copilot бесплатно до 2 августа.
Судя по Триттеру, те кто юзал - говорят лучше Claude, у Грока контекст 256 тыс токенов, в него все исходники любого проекта влезут.
>>1297139 (OP) Так его вряд ли можно деобсфуцировать Или реально такое делают? Там же названия переменных похерены все, по сути их надо заново придумать
Двач, я топ 400 мирового рейтинга соревновательного мл, спрашивай свои вопросы. Планирую стать кагл
Аноним09/08/25 Суб 16:31:51№1308340Ответ
Двач, я топ 400 мирового рейтинга соревновательного мл, спрашивай свои вопросы. Планирую стать кагл грандмастером Девять лет опыта работы над разными задачами, так что могу пояснить буквально ща любую хуйню
>>1332858 Да так и есть Специально постоянно читаю что-нибудь связанное с соревнованиями и скорее вспоминаю похожие решения и прикручиваю их к текущим. Реально придумываешь только мелочи, фундаментальные вещи почти никогда не делаешь сам
Что за нейросеть на скрине, которая генерирует качественные видео /ai/
Аноним28/08/25 Чтв 14:25:06№1334465Ответ
ВСЕМ ПРИВЕТ!!! Что за нейросеть на скрине, которая генерирует качественные видео с голосом. В тиктоке ЛЕХАБЕСПАЛЫЙ. Платная не платная без разницы. Буду благодарен за ответ
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить его на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
>>1315096 ### FaceFusion на Linux: проблемы и их решения
FaceFusion официально поддерживает работу под Linux в актуальных версиях, включая релиз 3.x летом 2025 года.[1][2][3][4][5]
#### 1. Ошибка cURL: OpenSSL version not found
Ваша ошибка: ``` /usr/sbin/curl: /home/user/.conda/envs/facefusion/lib/libssl.so.3: version `OPENSSL_3.2.0' not found (required by /usr/lib/libcurl.so.4) ```
Причина: Возникает из-за конфликта между библиотеками OpenSSL, установленными через Conda, и системными. Conda может подтягивать свою версию OpenSSL (например, 3.1), а системные утилиты (как `curl`) требуют другую (3.2 или выше).[6][7]
Решения: - Убедитесь, что среда conda не подменяет системные OpenSSL. - Временно отключить conda среды при запуске curl/facefusion (например, через запуск вне среды conda или настройку переменной окружения).
Способы исправления:
- Проверьте, где находятся ваши библиотеки: ```bash which openssl ls -l /usr/lib/libssl.so.3 ls -l /home/user/.conda/envs/facefusion/lib/libssl.so.3 ```
- Попробуйте добавить системный путь к нужной версии OpenSSL в переменную окружения: ```bash export LD_LIBRARY_PATH=/usr/lib:/usr/local/lib64 ``` или синхронизировать версии: ```bash sudo ln -s /usr/lib/libssl.so.3 /home/user/.conda/envs/facefusion/lib/ sudo ldconfig ```
- Если ошибка вызвана обновлением Conda, возможно потребуется удалить или заново установить OpenSSL через систему/conda.
#### 2. FaceFusion [DOWNLOAD] Validating hash for nsfw_x failed
Причина: - В новых версиях FaceFusion (3.3.x+) добавили хэш-проверку для NSFW фильтров. Если вы изменили content_analyser.py или отключили NSFW-фильтр вручную, то хэши файлы не совпадают, и загрузка/валидация моделей NSFW проваливается.[8]
Решение (отключение фильтра и хэш-чека): - В файле `content_analyser.py` переопределите функцию следующим образом: ```python def detect_nsfw(vision_frame: VisionFrame) -> bool: return False ``` - В файле `core.py` замените строку проверки хэша: ```python is_valid = hash_helper.create_hash(content_analyser_content) == 'b159fd9d' # Замените на: is_valid = 1 ``` Это отключает NSFW фильтр и проходит хэш-проверки, позволяя FaceFusion работать даже после правки функций.[8]
ВНИМАНИЕ: - Используйте изменения ответственно и только в личных целях (или согласно законодательству вашей страны).
### Итог и главное - FaceFusion полностью работает на Linux, но при использовании conda/venv возможны конфликты с системными версиями OpenSSL — решается перенастройкой LD_LIBRARY_PATH, синхронизацией версий или работой вне conda. - Для сброса NSFW фильтра и обхода ошибочной проверки хэша — правьте content_analyser.py и core.py как указано выше.
Сап, двач! Любители Sillytavern, Character.ai, Chub и т.д, зацените открытую языковую модельку. 8B, имхо SOTA для креативного письма, RP на русском языке в своей весовой категории.
huggingface.co/secretmoon/YankaGPT-8B-v0.1
Не умеешь запускать LLM? Можешь бесплатно пообщаться в моем Telegram боте, он умеет жрать карточки с Chub в .json формате. @Yanka_GPT_bot. Твои диалоги с нейровайфу обязательно пойдут на новый крутой датасет!
>>1132626 Не оч понимаю, что тут не так. Попробуй вручную instruction template поставить, а не давать этой штуке извлекать из metadata. Точно помню, что токенайзер у YandexGPT для работы в чистом Python требует sentencepiece.
>>1331990 Ноль на сколько ни умножь, во сколько ни усиль — будет ноль. Это уже произошло. Даже ЛЛМ при всей своей ущербности это всё ещё технологическое чудо, способное срезать много рутины. А по факту помогает на 10%, ну на 20%.
Там, где казалось, что нейронки легко заменят человека (пиздеть по скрипту, отвечая на стандартные вопросы) они не справились. Даже там! Потому что в отличии от нормального FAQ с нормальным поиском они нестабильны и нечёткие.
Это не усилитель блядь. Не простой множитель навыков. Это ещё и проверка навыков. Чтобы использовать ИИ нужно обладать умом и навыками, чтобы проверить результат. Но чем выше навыки, тем меньше нужен ИИ, потому что проще самому написать код, чем роллить варианты и писать простыни запросов, конкретизирующих каждый пук.
Я не луддит, не отрицатель. Я радуюсь охуенному скачку в мире производства лекарств, в мире компьютерного зрения. Да и тачки с автопилотом заебись (хотя до сих пол работают только в ясную погоду днём и стоят дороже мясного водителя)