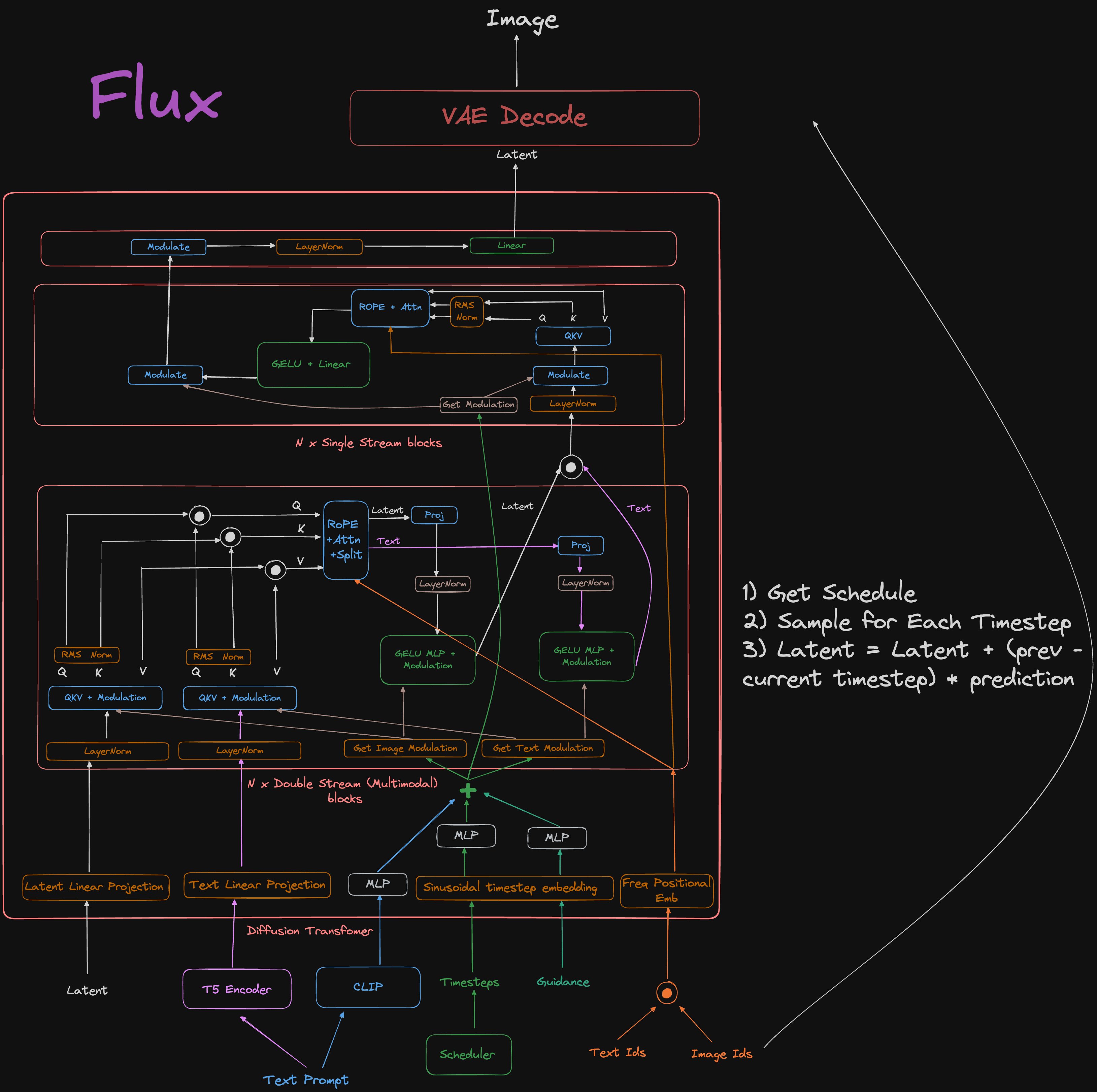
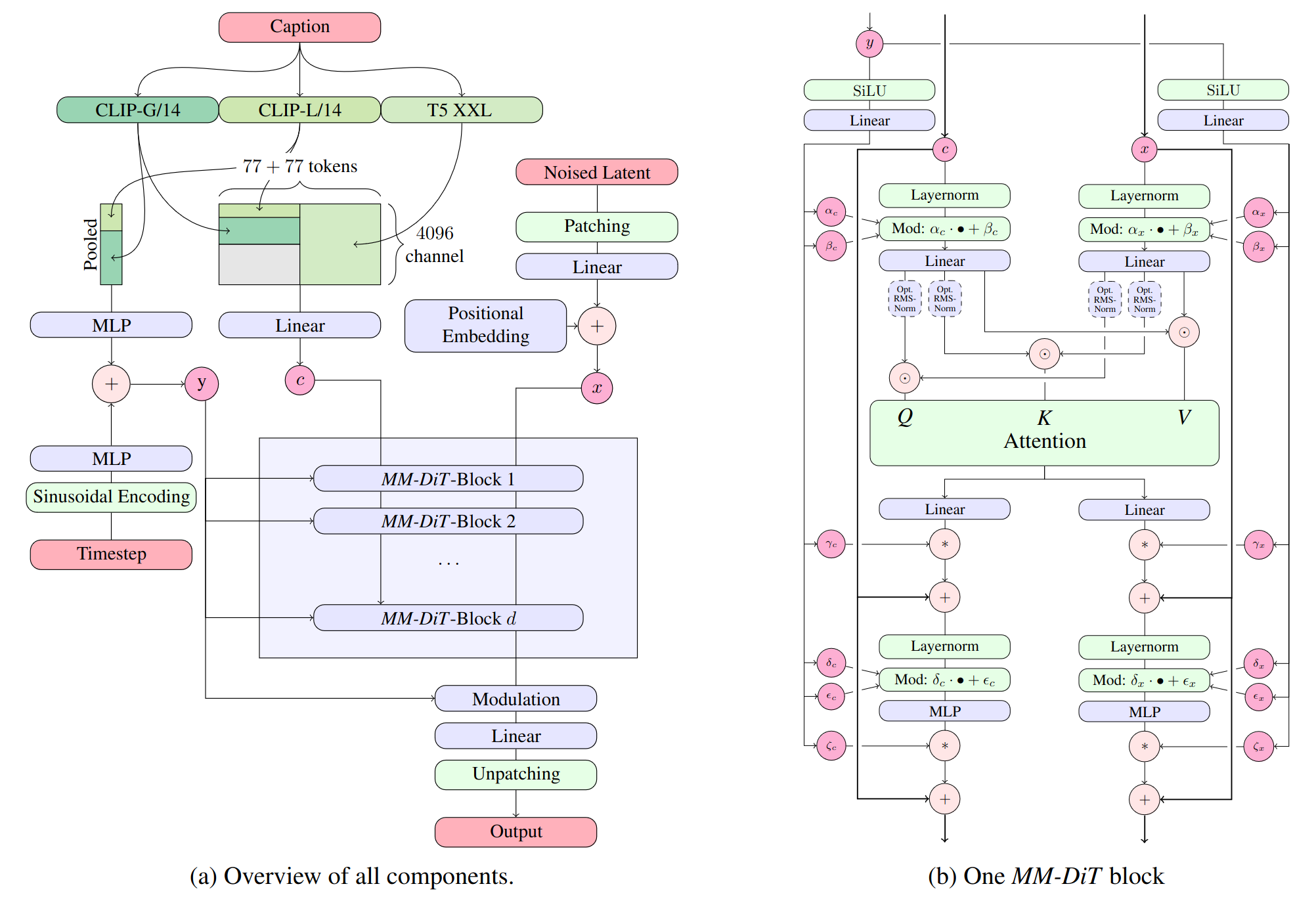
1. Доска предназначена для любых обсуждений нейросетей, их перспектив и результатов.
2. AICG тред перекатывается после достижения предела в 1500 постов.
3. Срачи рукотворное vs. ИИ не приветствуются. Особо впечатлительные художники и им сочувствующие катятся в собственный раздел => /pa/. Генераций и срачей в контексте всем известных политических событий это тоже касается, для них есть соответствующие разделы.
4. Это раздел преимущественно технического направления. Для генерации откровенного NSFW-контента без технического контекста выделена отдельная доска - /nf/. Эротика остаётся в /ai/. Голые мужики - в /nf/. Фурри - в /fur/. Гуро и копро - в /ho/.
5. Публикация откровенного NSFW-контента в /ai/ допускается в рамках технических обсуждений, связанных с процессом генерации. Откровенный NSFW-контент, не сопровождающийся разбором моделей, методов или описанием процесса генерации, размещается в /nf/.
>>1338247 >Так а гемини про разве не умеет это делать? Может и умеет, но в данном случае не использует. Это закрытые модели, внутре хоть индус сидеть может. >Открывал ссылку и видел там цитату, которую привёл грок Ну значит гугол.
Аноны, подскажите, попадались ли вам сайты, где можно почитать диалоги с gpt?
Подозреваю, что какие-нибудь бесплатные сайты, которые дают сколько-нибудь запросов к gpt могут публиковать такие диалоги. Вроде мне что-то такое даже попадалось когда-то, но не смог вспомнить адрес
Вышла версия 1.5 Allegro, по функционалу то же, что и 1.5, только в два раза быстрее. Лимит 400 кредитов в месяц (или 200 генераций по 33 секунды каждая) при условии ежедневного захода на сайт - 100 кредитов даются в месяц, и еще 10 кредитов даются ежедневно. Также можно фармить кредиты, выполняя специальные задания по оцениванию качества рандомных треков, это дает не больше 10 дополнительных кредитов в день. Для большего числа кредитов и более продвинутых фич типа инпэйнтинга или генерации с загруженного аудио нужно платить. Появилась возможность генерировать треки по 2 минуты 11 секунд, не больше 3 длинных треков (по 2 версии на каждый трек) в день на бесплатном тарифе.
Новинка, по качеству звука на уровне Суно или чуть выше. Лучший по качеству генератор текстов на русском. Количество генераций в день не ограничено, но за некоторые функции нужно платить (загрузку аудио, стемов и т.д.)
Это буквально первый проект который может генерировать песни по заданному тексту локально. Оригинальная версия генерирует 30-секундный отрывок за 5 минут на 4090. На данный момент качество музыки низкое по сравнению с Суно. Версия из второй ссылки лучше оптимизирована под слабые видеокарты (в т.ч. 6-8 Гб VRAM, по словам автора). Инструкция на английском по ссылке.
Еще сайты по генерации ИИ-музыки, в них тоже низкое качество звука и понимание промпта по сравнению с Суно, либо какие-то другие недостатки типа слишком долгого ожидания генерации или скудного набора жанров, но может кому-то зайдет, поэтому без описания:
______________ Напомню мега-сайт для сочинения аутентичных англоязычных текстов для ИИ-музыки в стиле известных групп и артистов от Пинк Флойда до Эминема. Зайти можно только через Дискорд.
>>1339641 >чтобы текст не проебался Что значит не проебался? То есть сгенерировать женеричное говно на 4ке это типа не проебется текст? Ты либо задрачиваешься и фиксишь текст на годном сиде, чтобы он звучал охуенно, либо он нахер не упал при любых раскладах. Качество же делается каверами в 4ку и микшированием разных дорожек, да и то далеко не всегда 4ка может выдать такой драйв и энергию как на 3ке.
Аноны, помогите пожалуйста. Мне почти 40 лет, недавно врачи диагностировали мне лимфому в 3 стадии, сколько проживу точно - не ясно, но знаю одно - осталось недолго. У меня есть 11 летний сын, который очень привязан ко мне. Я хочу, чтобы даже после моего ухода он мог поговорить со мной(хотя бы с моим голосом). Есть ли у меня возможность создать голосовой ИИ, который будет общаться моим голосом? У меня есть хороший микрофон и прочее, чтобы записать достаточно материала с моим голосом. Если найдется желающий помочь - то объясните мне в этом треде как для чайника, ибо я почти ничего не знаю об этой сфере.
>>1338547 > Снимать видео с собой ...Точнее - нужно снимать на видео свое общение с сыном и другими родственниками, чтобы в кадре были и сын и отец. Когда сын будет пересматривать, то он будет возвращаться мысленно и эмоционально в этот момент общения. И заодно и себя видеть каким он был тогда.
Короче нужно снимать побольше семейного видео, чтобы в видео были разные родственники, а не только одного себя. Стань как бы архивным блогером, придумывай сценарии, настольные игры, вылазки на природу, снимай это все на видео, не для публикации где-то на ютубе, а для семейного архива, отбирай лучшие ролики и архивируй их на CD-R.
>>1339673 > Стань как бы архивным блогером, придумывай сценарии, настольные игры, вылазки на природу, снимай это все на видео, не для публикации где-то на ютубе, а для семейного архива, отбирай лучшие ролики и архивируй их на CD-R. Или он может просто его изнасиловать и тот никогда его не забудет.
>>1338517 >К тому времени, через 20 лет всё это будет уже автоматически работать. Это уже сейчас можно сделать. Генератор голоса из 10 секундного отрезка аудио - есть. Липсинк для генератора видео есть и это все локально. В каком нибудь veo3 это вообще реализуемо в 2 кнопки.
Через 20 лет ты уже просто по памяти из головы будешь образ составлять и генерировать.
Локальные языковые модели (LLM): LLaMA, Gemma, DeepSeek и прочие №162 /llama/
Аноним31/08/25 Вск 00:33:06№1336982Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1339912 Что такое? Есть много моделей лучше эйра, но в своем классе он крут. Особенно хорош тем, что может быть запущен на десктопе и при этом справляется с решением простых-средних задач с вызовами. >>1339914 С какими параметрами запускал? С него в основном плюются что наоборот с мультигпу медленнее, и сам автор это признает.
Мда, без фа ваниллу запустить нереально. Просит 8 гб лолоцировать на куде 0. Щас конечно попробую скинуть пару слоев в рам, но если он на каждом девайсе будет столько просить - пошел он нахуй этот ваш жора.
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 8322.64 MiB on device 1 ggml_gallocr_reserve_n: failed to allocate CUDA1 buffer of size 8726917120 graph_reserve: failed to allocate compute buffers llama_init_from_model: failed to initialize the context: failed to allocate compute pp buffers
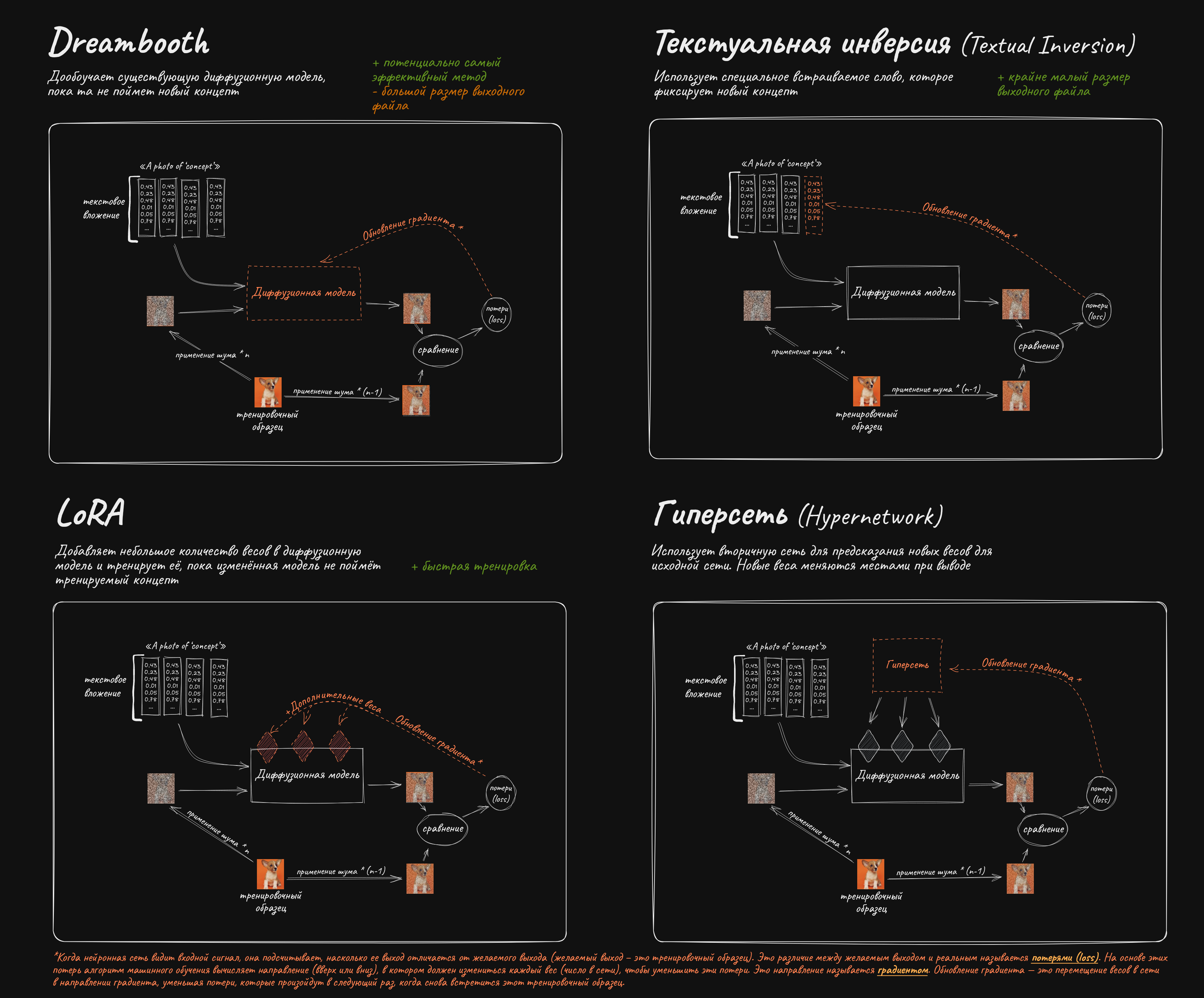
ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
>>1339764 В каком месте бля? >loss = mse_complex(dfrft(model_pred.float(), 0.5), dfrft(target.float(), 0.5)) Разница между таргетом и предиктом и есть лосс по спектру генерации который на разных таймстепах должен быть разным. Если тебя смущает то что это происходит в пространстве шума а не исходной картинки, то спектр и все его свойства зеркально соответствуют картинке. Выделение низких частот будет фокусировать модель на низких, высокие частоты шума соответствуют высоким частотам картинки. На разных таймстепах разный диапазон критичных ошибок и диапазон невозможных для модели предсказаний на которые ее бессмысленно дрочить. В идеале бы это логировать и добавить автоматику которая будет клампить какой-то процент ошибок по спектру, или как-то считать дисперсию ошибок, кароч там должно автоматически настраиваться и без шедулинга, интуиция тут в том чтобы модель работала всегда в диапазоне "зоны ближайшего развития" https://ru.wikipedia.org/wiki/Зона_ближайшего_развития
>>1339843 > Выделение низких частот будет фокусировать модель на низких, высокие частоты шума соответствуют высоким частотам картинки. Ещё раз - у тебя нет там картинки, у тебя шум. Высокие частоты шума не соответствуют высоким частотам картинки. Шум который ты сравниваешь, в лоссе target - это то что из генератора шума получено. Чтобы получить картинку, утрировано тебе надо вычитать аутпут модели предсказанный шум из инпута латент + шум из генератора. Чтоб сделать то что ты хочешь надо делать шаг деноизинга в шедулере шума и сравнивать непосредственно спектры картинки, но тут ты попадёшь в похожую яму что и с wavelet - всегда будет перекос куда-то там у нас перекос потому что wavelet неравномерно декомпозицию делает и надо весами потом крутить. Тогда да, надо пердолиться с подстраиванием под timesteps на глаз. Собственно fft просто работает без пердогинга как раз потому что мы никак не взаимодействуем с картинкой и её спектрами. Лучше альфу покрути вместо 0.5 повышай до 1.0 и дальше с шагом 0.5 иди вплоть до 5.0, если хочется какого-то другого результата.
>>1339909 >Ещё раз - у тебя нет там картинки, у тебя шум. >Чтобы получить картинку, утрировано тебе надо вычитать аутпут модели Вычитание никак не влияет на спектр. Нет разницы в спектре между лоссом картинка - предсказание картинки и шум - предсказание шума.
Новости об искусственном интеллекте №33 /news/
Аноним26/08/25 Втр 16:44:15№1332558Ответ
>>1339599 Настоящий Яндекс остался в Нидерландах под защитой НАТО. Вот для чего нужен НАТО. А то что осталось - тень от Яндекса, как АвтоВаз - тень от Фиата.
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
https://elevenlabs.io перевод видео, синтез и преобразование голоса https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске >>
Как же бомбит-то, сука Я несколько грёбаных вечеров слил просто вникуда, как будто их не было Всего лишь сделать то же самое, что делают тысячи других людей, и я явно не самый тупой из них У них всё получается, всё работает, вон сколько обучающих видео, сколько статей, гайдов Я пробовал использовать скетчбуки (тысячи их), с забитыми примерами - они не работают; Я качал готовые "portable" сборки, где не надо ничего настраивать - они не работают; Да блять даже из шапки этого треда запускаю гайд для конченых долбоёбов "нажми одну кнопку и будет хорошо" - один хуй не получается нихуя, у меня даже не было возможности что-то сделать не так;
Что это за магия ебаная, как у вас всех это всё работает? Может, мне к кому-нибудь домой прийти и попробовать запустить? Я уверен, тоже нихуя не будет работать.
Аноны, у меня вопрос не совсем по нейронкам, но по tts. Решил попробовать послушать книжки через tts (в fdroid есть sherpatts, там модельку скачал ru irina medium) и вроде неплохо. Но нужны словари для правки ударений и прочих произношений. Может быть кто-то знает где их взять или может быть можно их сгенерировать прямо из текста книги?
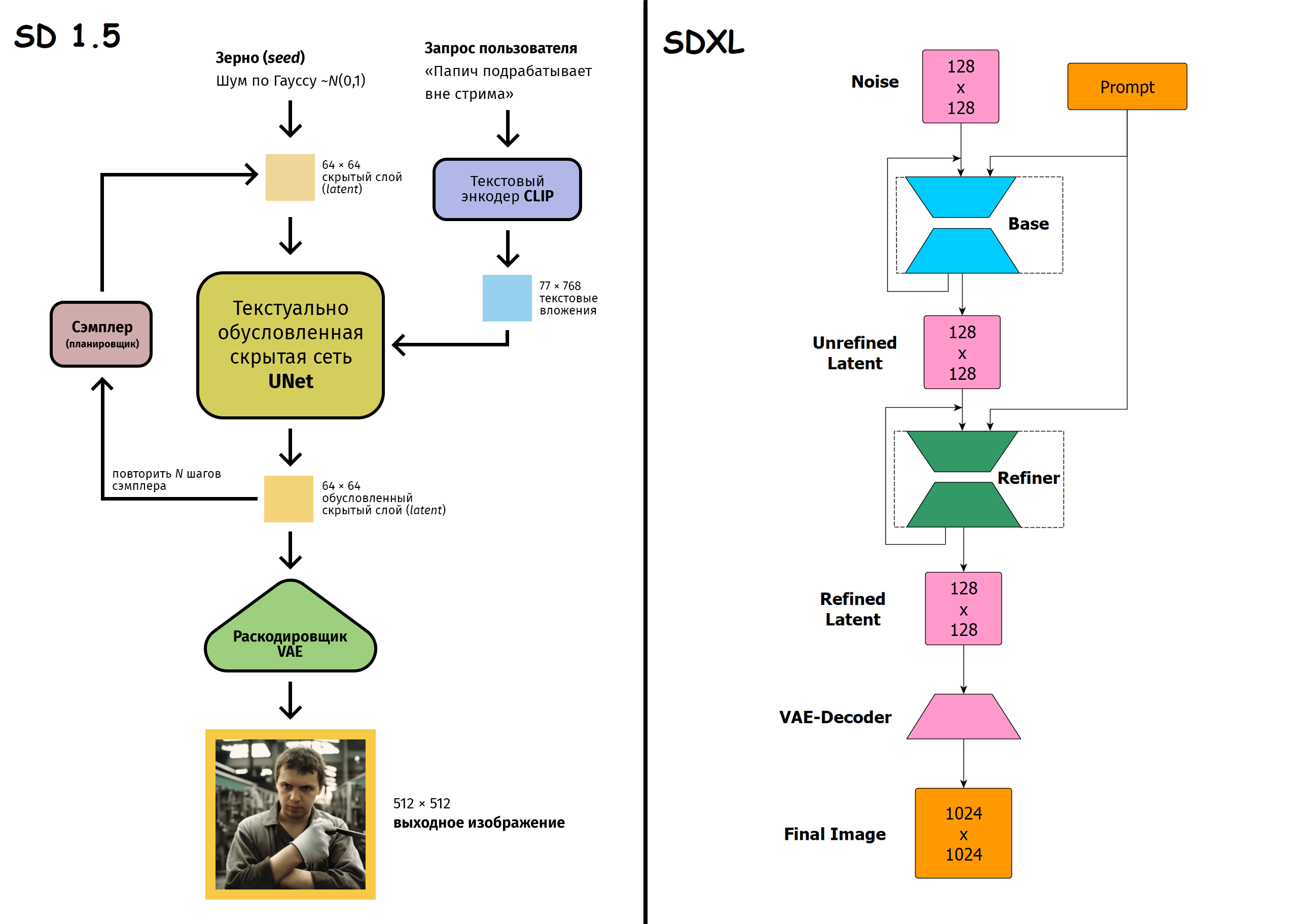
Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
Midjourney — это исследовательская компания и одноименная нейронная сеть, разрабатываемая ею. Это программное обеспечение искусственного интеллекта, которое создаёт изображения по текстовым описаниям. Оно использует технологии генеративно-состязательных сетей и конкурирует на рынке генерации изображений с такими приложениями, как DALL-E от OpenAI и Stable Diffusion.
Midjourney была основана в 2016 году одним из создателей технологии Leap Motion Дэвидом Хольцем и в феврале 2020 года была поглощена британским производителем медицинского оборудования компанией Smith & Nephew. С 12 июля 2022 года нейросеть находится в стадии открытого бета-тестирования, и пользователи могут создавать изображения, посылая команды боту в мессенджере Discord. Новые версии выходят каждые несколько месяцев, и в настоящее время планируется выпуск веб-интерфейса.
Господа аноны, можно реквест? Розовый УАЗ "Буханка" с цифрой 7 на двери стоит на обочине. Три мужчины, стоят спиной. Первый мужчина толстый. Второй мужчина в очках и с бородой. Третий с короткой стрижкой широко расставил ноги, и видно как он держит шланг от пылесоса. Кажется, что они ссут на машину, но на самом деле держат пылесосы. Картинка, видео не нужно. Заранее благодарю, с меня нихуя.
Общаемся с самым продвинутым ИИ самой продвинутой текстовой моделью из доступных. Горим с ограничений, лимитов и банов, генерим пикчи в стиле Studio Ghibli и Венеры Милосской и обоссываем пользователей других нейросетей по мере возможности.
Общение доступно на https://chatgpt.com/ , бесплатно без СМС и регистрации. Регистрация открывает функции создания изображений (может ограничиваться при высокой нагрузке), а подписка за $20 даёт доступ к новейшим моделям и продвинутым функциям. Бояре могут заплатить 200 баксов и получить персонального учёного (почти).
Гайд по регистрации из России (устарел, нуждается в перепроверке): 1. Установи VPN, например расширение FreeVPN под свой любимый браузер и включи его. 2. Возьми нормальную почту. Адреса со многих сервисов временной почты блокируются. Отбитые могут использовать почту в RU зоне, она прекрасно работает. 3. Зайди на https://chatgpt.com/ и начни регистрацию. Ссылку активации с почты запускай только со включенным VPN. 4. Если попросят указать номер мобильного, пиздуй на sms-activate.org или 5sim.biz (дешевле) и в строку выбора услуг вбей openai. Для разового получения смс для регистрации тебе хватит индийского или польского номера за 7 - 10 рублей. Пользоваться Индонезией и странами под санкциями не рекомендуется. 5. Начинай пользоваться ChatGPT. 6. ??? 7. PROFIT!
VPN не отключаем, все заходы осуществляем с ним. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
Переводчик из него, просто мама мия нахуй. В первом посте он говорит лучше заменить "¡Wow!" на "¡Guau!", во втором посте говорит заменить "¡Guau!" на "¡Wow!". Переводчик с биполярочкой...
>>1339306 В данном случае в сто раз лучше было бы сделать инпейнт сисек через VACE. >>1339393 Это всё в дефолтных нодах Kijai, пример воркфлоу тоже лежит в samples.
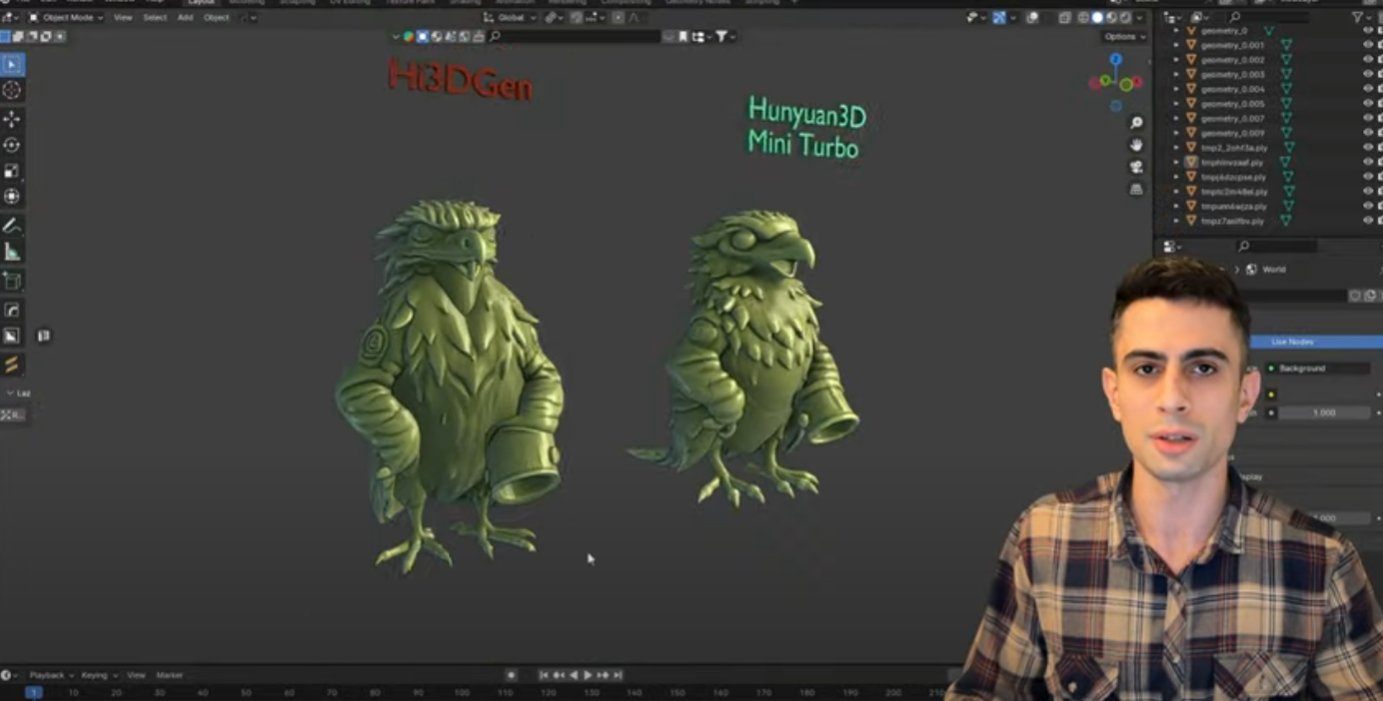
В этом треде обсуждаем нейронки генерящие 3д модели, выясняем где это говно можно юзать, насколько оно говно, пиплайны с другими 3д софтами и т.д., вангуем когда 3д-мешки с говном останутся без работы.
Как-будто Тьюринг тест в привычном его понимании пройден безвозвратно. Все ещё есть паттерны и закономерности, но по параметрам человечности, вряд ли осталось много отличий.
>>1230451 ты лошарик когда ии выйдет из под контроля, он оставит только тех кого ему нравится (меня), а тебя будет ебать в жопу пока ты не умрешь от пролапса
Claude тред №2 /claude/
Аноним30/07/23 Вск 17:28:42№435536Ответ
В этом треде обсуждаем семейство нейросетей Claude. Это нейросети производства Anthropic, которые обещают быть более полезными, честными и безвредными, нежели чем существующие помощники AI.
Поиграться с моделью можно здесь, бесплатно и с регистрацией (можно регистрироваться по почте) https://claude.ai/
У Бананы есть полный контроль позы или только примерный, по принципу "вижу падающего человека на примере, значит персонаж тоже должен падать"? Ракурс, положение частей тела, поворот головы можно переносить? Или это пока рандом?
существуют ли заранее настроенные нейросети для решения математических задач, например chat GPT усл
Аноним29/05/25 Чтв 13:50:33№1222633Ответ
существуют ли заранее настроенные нейросети для решения математических задач, например chat GPT условный заранее настроенный, АИ агенты может какие-то готовые, как вообще такое можно поискать?
>>1222633 (OP) да. huggingface.co + ollama.com твоя цель - LLM (Large Language Model) большие языковые модели. Есть модели файнтюненые под решение мат задач. За доп информации можешь заглянцть дрочерам в /llama/ трэд. Но они больше про CUUUUMMMMING!!! Ставишь ollama с одноименного сайта, накатываешь open-webui (с тройным разрывом ануса если не умеешь в консоль) Базовые модели есть на ollama, всё остальное на huggingface, гугл в помошь
Клянчу гпу итт. И ещё старые пикчи тоже.
Аноним21/05/25 Срд 15:53:24№1210535Ответ
Сап. Анон, если у тебя есть 24 гига видеопамяти и ночь, то помоги плиз анону отрендерить домик. Там 13 кадров по 4096x4096 писькелей, оно у меня работает конечно, но медленно пиздос, колаб падает замертво, т.к. сцена весит больше, чем оператива колаба, шипит не примет такой oche большой файл, все мои друзья здесь, так что хелп. >как Скочать блендер последний https://www.blender.org/download/, скончать файл проекта https://drive.google.com/file/d/11serzTv6XqzS8aXovkEkWddoRE_qU9-O/view?usp=sharing, распаковать его в папку какую-нибудь, открыть .blend файлик в блендере и нажать cntrl+f12, пойдёт рендер. >Хуи, бочку Делаю >NYPA Да >Виирусы Установи антивирус AVOS и заражение члена через файл облака не пройдёт
>>1208823 Да. Я же не в тестах карты гонял. Тупо брал и автоматик1111 накатывал и картинки генерировал. Там вроде Р5000 даже с каким-то другим стартовым параметром приходилось запускать и поэтому она оказалась медленнее.